%20(1).png)
The Knowledge Processing Unit™
The computational engine in most devices today is a general purpose processor or digital signal processor. The basic architecture of either is a variation on the Random Access Machine, also called a stored program, or von Neumann machine (John von Neumann). It consists of a central processing unit requesting instructions and data from a common, shared memory. The processing element fetches an instruction from memory, decodes the instruction, which typically triggers one or more requests for operands (=data) from the same common memory, before finally scheduling the execution of the instruction, and subsequent write back of the result. This process was the most effective solution for execution when processing elements where very expensive and bulky.
In 40nm chip technology, the silicon area occupied by a register element is roughly comparable to the area occupied by an arithmetic/logic unit (ALU). Moreover, the typical microprocessor allocates about 60% of its transistors in the processing pipeline to the instruction fetch, decode, and scheduling stages. Since memory latency has improved much slower than processor clock periods over the past thirty years, there is an extra-ordinary mismatch between the request/response cycle and the raw instruction dispatch rates of modern processors; in one memory cycle a processor can dispatch a thousand instructions or more.
The final limiting constraint for the sequential processor is power consumption. Since 2003, the performance of sequential processors has leveled off, mainly due to power density constraints. This has lead to multi-core architectures to occupy the available transistors of continuously improving chip manufacturing technologies. Unfortunately, programming many cores to collaborate on the same problem has been an unsolved problem since the 60's when the first multi-processor machines where built. Instead, the cores have been used to support independent concurrency in the form of virtual machines, and OS services concurrency.
The inefficiency of the sequential processing pipeline combined with the increased complexity of writing software to take advantage of multi-core processors has severely limited the ability of intelligent systems to leverage the available compute capacity of modern silicon technologies. Modern high performance microprocessor have performance/power densities in the range of 0.5-5GFlops/Watt. However, the raw silicon capability is measured in the hundreds of Gflops/Watt. The Stillwater KPU, which is a true parallel execution engine, regains much of this available performance, and can deliver performance/power densities in the range of 1TOPS/Watt.
The Stillwater KPU is a Domain Flow Architecture™. Domain Flow machines are distributed data flow machines that support distributed data structures. They are programmed through single assignment languages that capture the data distribution. Domain Flow machines differ from Data Parallel machines, such as many-core GPUs, in that the data distribution can be any arbitrary domain.
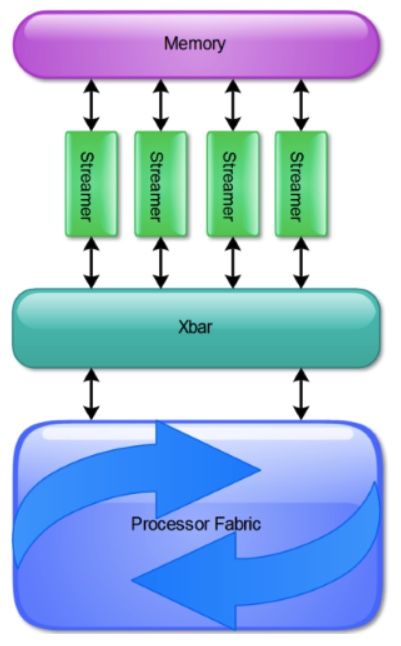
As shown in Figure 1, the Stillwater KPU consists of a compute fabric connected to random access memory via a set of streamers. The KPU fabric is the network of processing elements that enable the computation on domains. The network topology is a 2D torus which enables the KPU to support very large computations as the activity wavefronts simply fold back into the 2D lattice.
The streamers are address generation units that are capable of traversing data structures in a random access memory and transform these data structures into data streams that are written into the fabric. The KPU processor fabric is a distributed data flow machine and thus has no notion of random access memory. All translations between flat memory data structures and spacetime schedules are created by the streamers. The Xbar connects the streamers to any row or column on the 2D torus.
The Stillwater Knowledge Processing Unit is an ideal solution to the problem of creating scalable, real-time intelligent systems -- particularly where power constraints on the entire system are important. The distributed data flow architecture provides a low-power, high-performance execution engine that is tightly matched to the characteristics of the constraint solvers that make up the computational bottleneck for creating intelligence. This enables new levels of performance in embedded applications where high performance processing is used to imbue the device with autonomous behavior, or value-added services to the human-machine interface. Finally, the domain flow programming model provides a high-productivity software development environment to describe fine-grain parallel algorithms without the burden of having to express scheduling, resource contention resolution, and thread coordination. The Stillwater KPU providing the execute engine that takes care of all the constraints by directly executing the data flow graph of the algorithm.
For more information about how to program Distributed Data Flow machines, take a look at the DFA documentation or play with the interactive splash screen.